The Disconnect
Supply Chain Planning runs in cycles. The real world never stops.
By Monday morning, the plan published Friday is already wrong. Demand shifted. A supplier slipped. A quality hold landed Sunday, and the next planning cycle is a week away.
Autonomy collapses this latency. AI agents turn your strategic intent into decisions in seconds, not weeks, and surface only the decisions where your judgment creates real value.
Not faster software. A different operating model.
Monday, 7:00 AM
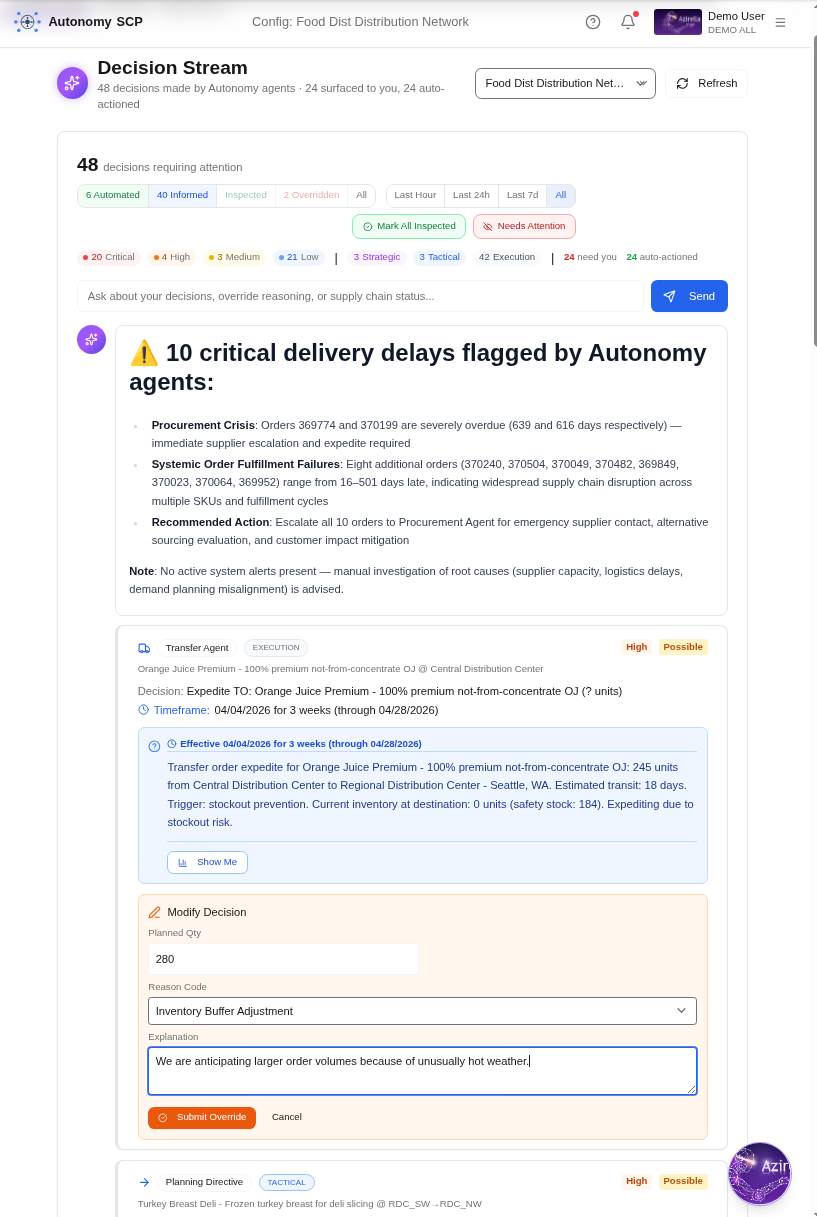
From 847 exceptions to 14 decisions.
A planner arrives to 847 exceptions across the network. Autonomy's agents have already evaluated every one, and already acted.
612
Auto-resolved
High likelihood, the agent decided
Automate
168
Abandoned
Low urgency, low likelihood, noise
below the Inform threshold
53
Informational
Handled, flagged for awareness
Inform
14
Inspect & Override
High urgency, low likelihood, her judgment matters
Inspect → Override
She spends her morning on the 14, reads the agents' reasoning, and overrides where she knows something they didn't. Every override becomes Operating Knowledge, the system learns the pattern, not just the correction.
She's not processing exceptions. She's managing decisions.
AI·IO·ML
You set intent. Agents decide. You apply judgment.
The agent acts. The human engages. The system improves. Most enterprise AI puts the human in the loop and makes them the bottleneck. AI·IO·ML takes the human out of the loop and gives them two first-class ways to stay in control: Inspect and Override.
Automate
Decides and acts continuously, within declared bounds. No approval queue, no waiting for Tuesday.
Inform
When calibrated confidence is low and the stakes are high, it surfaces the decision so you know why to look. The action is already committed.
The agent decides by default and says so.
Inspect
Open any decision and read its prompt, reasoning, expected outcome, and calibrated likelihood. Inspection is how trust is built.
Override
Supersede the agent with a new, better-informed decision when you know something it didn't. Not undo, a new decision, captured as Operating Knowledge.
The human reads in, and writes back.
Measure
Every decision and every override is scored against its counterfactual outcome. Cost avoided, revenue protected, error magnitude, all observable.
Learn
Agents retrain on every (decision, outcome, override) triple. Calibration tightens, and more decisions safely move into Automate.
Every cycle the policy gets sharper.
The agent decides. The human knows. The system learns. Every cycle of the loop tightens calibration and shifts more decisions safely into Automate.
Trust earned by measurement, not granted by trial.
Auto-executed decisions as a share of total volume. Every cycle tightens calibration and moves more decisions safely into Automate.
Week 1
~45%
Auto-executed decisions
Week 12
~72%
Auto-executed decisions
Steady state
~85%
Auto-executed, <10% overridden
BCG's 1/4-2-20 rule: every quartering of decision cycle time doubles labor productivity and cuts costs by 20%. Moving from weekly to continuous planning applies that rule not once, but repeatedly.
George Stalk Jr., "Rules of Response" (BCG Perspectives, 1987)
Latency compounds costs. Velocity compounds value.
Four Pillars of Autonomous Planning
Each capability reinforces the others, creating a self-reinforcing advantage that gets stronger with every decision.
AI Agents
11 specialized agents operate as a coordinated hive, biologically-inspired roles that communicate through a real-time signal system. From ATP allocation to purchase orders to manufacturing execution. Each decision is explainable and overrideable.
- A2A protocol, open agent interoperability
- <10ms inference latency
- Continuous learning from outcomes
- 24/7 operation, agents never sleep
Causal AI
The only rigorous way to know if a decision worked. Counterfactual reasoning compares what happened to what would have happened, separating decisions that caused good outcomes from decisions that got lucky.
- Counterfactual decision evaluation
- Causal override effectiveness
- Learn from skill, not luck
- Evidence-based guardrail calibration
Conformal Prediction
Every agent decision carries a distribution-free likelihood guarantee. Stochastic planning generates the calibration data; conformal prediction wraps it in mathematical coverage bounds that hold regardless of distribution.
- Distribution-free coverage guarantees
- Powered by stochastic simulation data
- Adaptive for non-stationary data
- Principled human escalation
Digital Twin
A complete simulation of your supply chain that generates the data everything else depends on. Monte Carlo simulation across 1,000+ scenarios produces training data for agents and calibration sets for conformal prediction.
- 20 distribution types
- Monte Carlo scenario generation
- Agent training data & counterfactual simulation
- Conformal prediction calibration sets
Grounded in Gartner's Decision Intelligence framework, sequential decision analytics, and peer-reviewed causal inference. Technology →
Ready to see Autonomy in action?
Agents handle the repetitive. Your people do the work that matters.